德客猫新闻资讯
作者:佚名 发布时间:2026-05-02 阅读: 转至微博:

|
DeepSeek V4到底能不能打?上线三天,第一批真实测试的结果陆续出来了。 它的纸面数据很猛,参数量最高到了1.6万亿,上下文窗口拉到100万token,API价格比GPT-5.5便宜了一个数量级。但三天下来最让人意外的,不是顶配的Pro,而是最便宜的Flash。有人拿20个真实任务把V4的四个版本全测了一遍,结果Flash赢了7个,好几个编码任务里它用更少的token,做出了和贵几十倍的Pro一样甚至更好的结果。 当然它也没强到可以闭眼吹。碰上复杂工程落地、精致前端、第一次就得成活的任务,GPT-5.5和Claude Opus 4.7仍然更稳。V4没有全面超车,但它正在把这场竞争从“谁最强”推向“谁最适合干哪种活”。
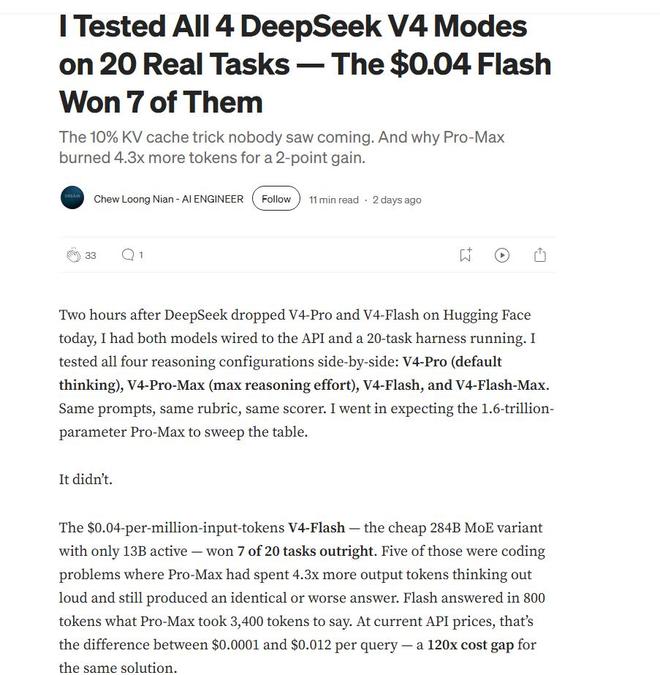
01实测出真知:最便宜的Flash,成了最大黑马? 很多人拿到新模型的第一反应,就是开最强的模式,跑最狠的测试。 但AI工程师Chew Loong Nian不这么想。他在DeepSeek V4发布后几小时内,就搭建了一个包含20个真实世界任务的测试框架,把V4家族的四个模式全部拉出来遛了一遍,分别是V4-Pro、V4-Pro-Max(最大推理努力)、V4-Flash,还有V4-Flash-Max。 这里需要先理清这几个模式的区别。DeepSeek V4分成了Pro和Flash两条产品线。Pro是更大的选项,参数达到1.6万亿,面向更深度的推理、更难的编码任务、研究以及长上下文工作。Flash则是更小、更快的选项,总参数2840亿,仅13亿激活参数,专为速度、更低成本以及需要重复调用模型的智能体工作流而生。 在这两个版本之上,用户还可以选择是否开启“深度思考”模式。开启之后,模型会花更多时间进行推理,在解决问题时展示出每一步思考过程,这通常会改善最终结果,但代价是响应速度变慢。 Chew Loong Nian的测试,就是把这四种组合并行投入实战。他的测试任务不是什么抽象基准,而是实打实的编码、Agent工作流、复杂推理和实际项目等场景。
结果让人大跌眼镜。赢的不是参数最大、思考最深的Pro-Max,而是最便宜、最轻量的Flash。就是这个每百万token输入成本仅约0.14美元的模型,在20个任务中硬生生拿下了7个第一。 其中5个是编码任务。在这些任务里,Pro-Max虽然思考了更久,输出的token量是Flash的4.3倍,但最终的答案却和Flash相同,甚至更差。一个典型的场景是,Flash用800个token就干净利落解决的问题,Pro-Max要花掉3400个token,成本相差了大约120倍。 这个发现很反直觉,但也很致命。它揭示了一个容易被忽视的事实,即更贵的模式、更深的思考,并不一定带来更好的实际产出。很多时候,Flash之所以能赢,恰恰是因为它没有被过多的思考带偏方向,反而更直接地命中了问题的核心。 Chew Loong Nian总结道,除非你的任务特别需要极致的深度推理,否则开发者在实际项目中应该优先考虑Flash。它用实际表现证明了,在大多数真实场景下,性价比并非一种妥协,本身就是一种强大的能力。 他还提到了DeepSeek在KV Cache压缩上的一个创新,被形容为没人预见到的10% KV缓存技巧。正是这项技术,让Flash能在极低的成本下依然维持高水平的性能表现。这是支撑其性价比优势的工程底座。 02 Pro的对手,是另一个维度的“人” 当然,这不代表Pro版本就弱。恰恰相反,DeepSeek给V4-Pro定的目标,直接对标的是当今世界的顶级闭源模型。 《麻省理工科技评论》引用了DeepSeek官方分享的基准测试结果,指出V4-Pro的性能与Anthropic的Claude Opus 4.6、OpenAI的GPT-5.4和谷歌Gemini 3.1相当。与其他开源模型相比,比如阿里巴巴的Qwen 3.5或Z.ai的GLM 5.1,V4在编码、数学和STEM问题上全面超越,成为有史以来最强大的开源模型之一。 但在一些第三方汇总的评估中,它与头部模型的差距依然存在。 专注AI新闻分析的网友@thehypedotnews根据一个名为人工智能分析智能指数的评估框架,给出了这样一组对比。如果将顶级模型的能力指数化,GPT-5.5是60,Claude Opus 4.7是57,DeepSeek V4-Pro则是52。
性能低了约13%,但价格呢?
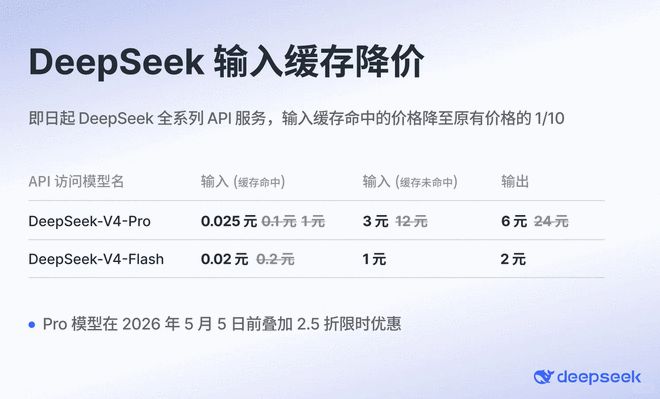
他紧接着算了一笔更让人震撼的账。每百万token输出价格的加权平均值,在不考虑任何折扣的情况下,GPT-5.5是30.21美元,Claude Opus 4.7是25美元,而DeepSeek V4-Pro只要1.73美元。
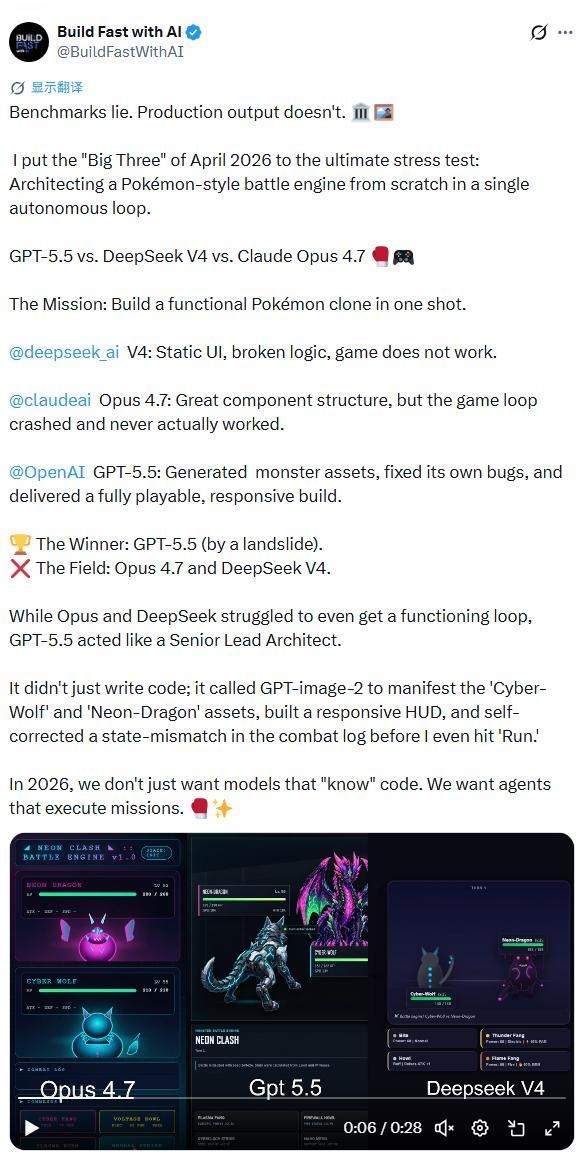
更狠的是,如果在V4发布初期的75%促销折扣期间使用,Pro的输出价格会进一步降至0.87美元每百万token。这个价格,比GPT-5.5便宜了35倍,比Claude Opus便宜了29倍。 用13%的性能差距,换一个35倍的价格优势,这已经不是同一个维度的竞争了。@thehypedotnews评论说,当一个模型能以6%的成本提供87%的能力时,我们更优秀就不再是唯一的卖点了。AI的商业化应用,正在以一种粗暴的方式被商品化,而DeepSeek V4无疑是这场价格战最激进的发起者。 不仅如此,DeepSeek还进一步将输入缓存价格下调至原来的十分之一。开源版本采用MIT许可协议、允许免费自托管,同时云端API定价又极具攻击性,这种打法被形容为掌控市场两端。开发者既可以选择完全免费的本地部署,也可以以极低的成本调用云端服务。这给了使用者前所未有的灵活空间。 03实战的B面:当“跑分王者”遭遇“滑铁卢” 但性价比的账算得再漂亮,终究要经受一个检验。当这些模型被投入真实的、复杂的、不可预测的任务中时,纸面上的优势还能兑现多少? AI应用开发与测试团队Build Fast with AI设计了一场堪称残酷的终极压力测试。他们将2026年4月的三大巨头,即GPT-5.5、DeepSeek V4和Claude Opus 4.7,置于一个单一自主循环中,要求它们从零构建一个宝可梦风格的完整战斗引擎。这不是写个静态页面,而是要做出一个功能完整的游戏。
结果成了清晰的分水岭。GPT-5.5的表现被描述为以压倒性优势获胜。它不仅写了代码,还自主调用了GPT-image-2图像模型,为游戏生成了赛博狼和霓虹龙等怪物资源。它构建了一个响应式的HUD界面,并且在测试者说运行之前,就已经自我修正了战斗日志中的状态不匹配问题。整个表现,被形容为像一位资深首席架构师。 Claude Opus 4.7呢?组件结构写得很出色,但游戏循环崩溃了,从未真正运行起来。 而DeepSeek V4交出的答卷更为惨淡,那是一个静态的UI界面,逻辑存在错误,游戏根本无法运行。 在这场测试中,Opus和DeepSeek连一个功能循环都难以实现。Build Fast with AI借此提出了一个判断,到了2026年,我们需要的已经不只是能懂代码的模型了,而是能执行任务的智能代理,能自主规划、调用工具、修正错误、完整交付成果。 类似的挫败也出现在更垂直的领域。AI Agent开发与测试员@akokoi1分享了他用DeepSeek V4做量化交易的经历。策略和代码全线交给V4自己写。他接入了OKX刚开源的agent-trade-kit,一个MCP服务器,能把现货、合约、期权、网格交易、算法单的接口全部直接提供给AI调用。
他说,和传统的编程时代相比,现在的工作流完全变了。过去写量化交易,需要自己读交易所文档、封装REST和WebSocket接口、处理签名鉴权、踩限频的坑、做双向对账,代码里有一半都在处理这些基础设施。而现在,他只需要直接调用MCP工具拿K线数据、下单、设止损,把精力全放在描述策略逻辑上。 他坦言V4写代码本身是足够用的,逻辑顺、能看懂市场结构、能把指标拼起来。策略报告写得有板有眼,前端写得也很不错,非常自信。但跑起来就拉胯了。 自动运行了一天,一开始几笔是盈利的,之后就一直在亏损。他用“再这么亏下去裤衩都会亏没”来形容这种挫败感。模型在纸面上把策略分析得头头是道,代码看起来也像模像样,但一旦接入真实市场,面对噪音、波动和不可预知的边缘情况,就露出了破绽。 接下来他打算把同样的策略交给Claude Opus和GPT-5.5再各写一套,看看不同模型在量化策略这个具体场景上,风格和能力差异能有多大。 这些测试描摹出了V4的一个弱点。在需要复杂工程落地或高度复杂的真实代码库环境中,它的表现依然不尽如人意。虽然对于很多任务来说它是极具性价比的选择,但在面对最苛刻的编程挑战时,GPT-5.5和Claude仍是更可靠的选择。 这不是说V4不好,而是明确了它的边界。别当成能包揽一切的神器,至少在需要审美判断和工程精细度的工作上,GPT-5.5和Claude仍然更稳。 |