�¿�è������Ѷ
����:���� ����ʱ��:2026-06-13 �Ķ�: ת������

|
����ϵ���ڹ�������д������Ϊ��Ϣ����֮�ã��������κ�Ͷ�ʽ���
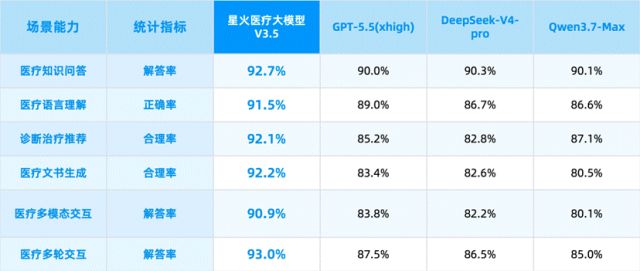
������꣬ҽ��AI�������¶ȣ��Ѿ�����Ҫ�б���֤���ˡ� 5��29�գ���������ί����֪ͨ��Ҫ���ǿ����ҽ�Ƶ����ǻ����ܣ���ȷ̽��AI������ϡ�����ǰ����˵ȼ�������ǰ�������������ӡ������ǿ������Ҫ���ƽ����˹�����+���ж�������ǰ���������й�2030�����岿ί���˹�����+ҽ��������ʵʩ�����AI�����������ҽ������Ŀ¼�������������Ӷ������һ·����������أ�����Խ��Խ�ܡ� �г�Ҳ�ڸ������¡�����������ʾ��2025�����AIҽ����ҵע������2.48��ң�ͬ������22.38%�����½�ʮ���¸ߡ�����ֽڡ��ٶȵ�ͷ���������Ƴ�AIҽ�Ʋ�Ʒ���������ٶ����ۿɼ��� ���۴����߶�����֧��·��������ҵ�����������ҽ��AI�Ѿ�����ˡ�������������۽Σ������ˡ�˭���������֡�����֤�ڡ� ����������ڣ�Ѷ��ҽ�ƽ����ijɼ������侪�ޡ�2025�����ҵ������Ѹ�ͣ�����ͼ�����ض�˵�����·������ǻ�ҽ�ƴ�ģ��V3.5��������ҽ��֪ʶ�ʴ���������Ƽ����������ɡ���ģ̬�����ȹؼ������ϣ�������������ԽGPT-5.5��DeepSeek-V4-Pro��Qwen3.7-Max������6��8�գ��Ϻ��˹�����ʵ����MedBench�����������У��ۺϵ÷�98.9�Ƕ���
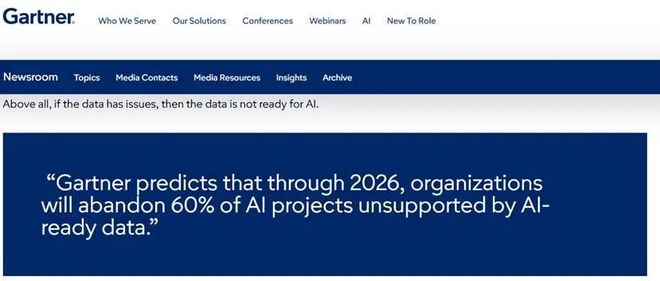
Ϊʲô������ȷ���Զ����У�Ѷ��ҽ�ƻ��Ϊ��������ߣ�����ӱ�����ĵײ����Ƶ�����ʲô�� 01 ���ݷ��֣������Ƶĵײ��ʲ� ȥ��2�£�Gartner������AI-ready�����ݲ���ĵ��б��棬Gartner��Ϊ�����㷨ģ����Գ����ǰ���£�����60%����Ŀ��û�����ó�ֵ������������ջᵼ����ҵAI���Ų�������
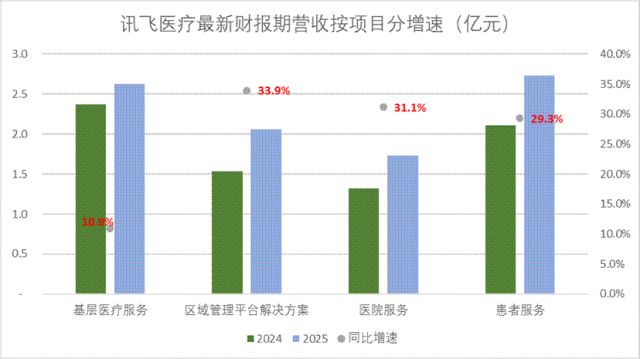
��ҽ�ƴ�ֱ���������������ϵ��ѷ��������ء����⼯���������������棺 ��һ��ҽ�����ݳ��֡�����˫ȱ�������������������β�룬����������Ӱ��ȷǽṹ�����ݴ���ȱʧ��¼����� ��������µ�ЧӦ����������ͬҽ����ϵ������ͬһ��ϵ�ڲ�ͬ���ҵ�����ϵͳ����������ͨ������ȱʧ�������ݱ�����ֶ��������ң���ģ������ֱ�Ӷ�ȡ�����ϡ� ������רҵ��ע�ɱ������ҡ�������Դ��һ����ҽѧ��ע��Ҫ�ٴ�ר����Ȳ��룬�ɱ��ߡ����ڳ���ͬʱ������Դ�����ڴ���д�ҽԺ������ģ���ڻ���ҽ�ƻ�������Բ�ͬ��Ⱥʱ�����������㡣 ҽ�� AI �������������������⡣ȥ���°��괨���ǿ����ȷָ����ҽ��ģ����ѧϰ�����١�����ƶ���֪ʶ�蹵����������ҵ�ձ���������� ������˫ȱ������һ��ӡ֤����һ��������ʼ������δ���� ��Щ��ҵ�ձ������⣬ǡ����Ѷ��ҽ�Ƶı������ڣ� �����ڽ�����ҵ�硢��������������ݸ������ϣ�����������ҽ�����Ѹ���ȫ��31��ʡ�г�800�����ء���7.7��һ���ҽ�ƻ�����B������600�ҵȼ�ҽԺ���Ƴ�������ǰ�����С�����ϵ��AI��Ʒ��Ӱ����ƽ̨�ۼƳ�1.6����Ӱ�����ݣ����ѽ���ϵ������ȫ�����ʡ�ݡ� ������ҵ�ձ鿨�ǵ����ݻ�����ͨ����������Ⱥ��Ļ��ڣ�Ѷ��ҽ��ͬ���߱���ϵ���Ľ�������� ���ؼ����ǣ�Ѷ��ҽ�����ȴ�ͨ�˻���ҽ�ƻ��� - �ȼ�ҽԺ - ������������������·�������˳��ڴ��ڵĿ�㼶���ݱ��ݣ�Ϊÿһλ�û�������ȫ�������ڵĶ�̬�����������ֿ糡������Դ�칹ҽ�����ݵ���Ȼ�ͨ�����������Ǿ������ֶ����ڶ������ƵĽṹ�����ơ�
�����ڴˣ��ǻ�ҽ�ƴ�ģ������16���˴�����ҽ���������ݡ�12�ڴ���ʵ�����������ݣ�����ƽ̨ÿ�������ij�220���������Ӱ��������ʵҽ�����ݣ��������γ�������������̫ЧӦ�� �����Ƴ����ǻ�ҽ�ƴ�ģ��V3.5��ҽ��֪ʶ�ʴ��������⡢��������Ƽ����������ɡ���ģ̬�����ȹؼ������ϣ�������������ԽGPT-5.5��DeepSeek-V4-Pro��Qwen3.7-Max��
��6��8���Ϻ��˹�����ʵ����MedBench�����������У��ǻ�ҽ�ƴ�ģ�����ۺϵ÷�98.9�ijɼ��Ƕ���ҽ�Ƴ�����֪�뽻����ҽ�ƶ�������Э����ҽ�ư�ȫ������Ϲ�ȶ����������λ�ӵ�һ�� �ͺñ�Coding����ǿ��Anthropic��ͨ������ǿ��ChatGPT����ҵ�ײ�������ͨ�ģ�ģ����������Ӧ�����ޣ�����Խǿ����صij����ռ��Խ�������з�Ͷ�������ת��Ϊ���������ݻ��ۣ������ֳ���������ģ�͵������������������ģ�ͣ�����������ҽ�Ƴ������ؿ����������ݵIJɼ���Χ���ɴ��γ�����ǿ���������������֡� �����ԣ�����AIҽ�Ʋ��棬Ѷ��ҽ�Ƶķ����Ѿ�ת�����ˡ���ν������羰���á��� 02 ʵ������������ת������ǰ������ ��������Ѷ��ҽ���ֽλ������Ƶ�ͬʱ��������Ҫ�������ǣ����ݷ�����ת��ǰ����ʲô���������ƾ߲��߱��ɳ����ԡ� ��ʵ�𰸷dz�������ǰ�����������������Ƶ�ǰ���������á�Ѷ���ǻ�ҽ�ƴ�ģ��V3.5����������ؼ����֣���������ҽ��������91%��Ӱ�������75%�� ��ôΪʲôѶ��ҽ�ƵIJ�Ʒ���ܵ�ҽ��������������һ�����������һ����ʵ������ҽԺ�����ҽ�����ںͻ��߶Ի���������ĽŲ�������������Ľ�̸������ʿվ�ĺ��������һ��ҽ��һ������һ���ü��̣�����ż���廰���������Բ��䡣�������ӻ����µĶ�˵��������ʶ�𣬱ȵ���˵����ͨ����һ���������� ����Ѷ��ҽ�ƣ������ų�������ѧ��Ӱ��ѧ����ҵKnow-how����ʵ�����˺�ǿ�Ķ�ģ̬��������һ�����ױ����ԡ� �����Ƴ��Ĵ�ģ�Ͳ�Ʒ�У�����ں�ҽ������ʶ��Ӱ�����ҽѧ��������Ķ�ģ̬����ȫ����������ҵ������ͻ����ʵҽ�Ƴ����£�Զ����˵��������ʶ���벡���Զ����ɵ�ʵ���ż�����Ӱ���ʿس�Խר�һ���ˮƽ�Ļ����ϣ��ǻ�ҽ�ƴ�ģ�ͽ�Ӱ��ʶ������������������Ƚ�ϣ�Ӱ����������ҵ���״ο�Խʵ���ż��� ���ⱳ�������Ǽ����ĵײ�ͻ�ơ���ȥ����ģ���ڴ������ı�ʱ���ڡ������ڶ��������������Խ�࣬�������ͻ��ָ��������������ҽ�Ƴ���ʵ�������������������ҵ���⣺һ��ҽ�Ƴ����£����������ֵIJ����ͼ�鱨�漫����ϵͳ�������ɱ������������ҽԺ���ػ�������Ͽ�Ҫ���ǹ�������ƽ̨��������ֳ����ı�ʱ������������̬���������⣬����ѵ������Ч�ʵ��¡� �����һʹ�㣬�ǻ�ҽ�ƴ�ģ�����ЕN��������Ⱥ���� MoE ϡ��ܹ��� DSA+MTP �Ż������������ȫ���������ع�������ʵ�� DSA ѵ��������ȫ����ԭ������֧�֣��Ż��ֲ�ʽѵ�����Խ�ѵ��Ч�������� 90%����ͨ������Ǩ�Ƽ������� 3 �������˴ӳ��ܵ�ϡ��ܹ��������л�����ģ��ѧ�������ҽ�Ƴ������ص���Ϣ�����벢������������ڹ����N�� 910B ��Ⱥ��ʵ��ҽ�Ƴ������ij�����������������4.5������һϵ�м���Ӳ��ͻ�ƣ���������������ҽ�Ƴ��ı��ı��ػ���Ӧ���⣬�����״�ͨ�˹�������ƽ̨������ƿ����ΪҽԺ������ҽ�Ʊ��ػ�����Ч�����ṩ�˼�ʵ�ĵײ㼼��֧�š� ���ʵ���ż���ֱ�ӽ��������ҵ������ͨ�������״�ҽ���������������ɡ�Ӱ���ѭ֤���������Ŀ��Ʒ�������ȴﵽʵ���ż���B������������ȷ�������ڿ��������� ���У���������ҽ���ĸ�ë�����²�Ʒ����ѭ֤�������������壬���������Ȩ������ָ�ϡ�ר�ҹ�ʶ�Ⱥ���������ҽѧ֤�ݣ���������������סԺȫ���Ƴ����������й����ƹ淶������ҽ˫��ϵ�� �����е���ҵ��DZ�����Զ����� 2022�������ҽ�ƿƼ���ҵOpenEvidence������õ���ȡ�OpenEvidence��һ������ҽ����AIҽѧ�������棬ͨ����Ѳ��Կ���������Լ65%��ҽ��Ⱥ�塣������ص��ǽ����ھ�ͬ������Ķ���ҽѧ����ѵ����Ϊ�ٴ������ṩ�����������Ŀ���Դ�𰸣��Ӹ�Դ�Ͻ����AI������ҽ�Ƴ����е��������⡣ 2025��7�£�OpenEvidence B�����ʺ��ֵ35����Ԫ�����������º��ֵԾ����60����Ԫ��2026��1�����D�����ʺ�ֵ������120����Ԫ��һ���ڹ�ֵ����12������Ϊ������AIҽ�������ֿ��ȵĶ�������ҵ��
|